Privacy & Go
I’ve been doing a lot of work recently for a non-profit organization to help my local community deal with private school tuition. The main reason I became involved was due to a very specific requirement about the system. A large number of the potential donors and participants did not want their private and personal financial information to be visible to the administrators and others. We are not talking about actual PII or “sensitive” information. None of the information here could actually be used to steal or harm our userbase. This is just information like how much they may annually. The basis of the program is that no family should have to pay more than 20% of their net income towards to tuition. They would pay 1% of their net income and be eligible to have the organization supplement what they pay. The focus of this article is the design decisions I made and why I made them. For more information about this organization you may visit https://ahavaschinam.org
Intro to Go
Let’s start with the main language of choice. I chose to use Go for the backend language. I am the CTO of this organization. No one else was involved in the technology team at the time. Whenever I am given the opportunity to design a system, the choices I make are extremely deliberate. I have been working quite a bit with Go recently and the one thing that screamed out to me is the simplicity in build, distribution, and execution. As long as you are running the same version of the Go tooling, you are more or less ready to go (no pun intended).
I knew the entire backend was going to be serverless. It was an is essential to me that I am never the sole contributor of a project. At the bare minimum, it is vital that a project be easy to hand off to others. When there are no other people yet involved you can try to pick very “commonly used” tools and technologies. That is however, not an exact science and totally subject to experience. Using Python or Javascript may have been the more popular choice, but that does not mean the better choice. Even for novices, I am a stickler for strongly typed languages. While Typescript is a greatly improved version of Javascript, I find the maturity of the tooling and libraries in the community are severely lacking. As for Python, I love Python, but the build, packaging, and distribution is much more complicated. Versioning is more tedious and simply more work to deal with for a team.
Go is easy. Go is simple. Go is elegant. Go is powerful. Go is good. For what its worth, I’m a recent Go convert. Go is now my goto language except for quick scripts and analytics which is most likely Python. Remember that all go builds are native. That means that performance will be as good as native code. Today we live in a world where many if not all of our code is serverless. We aren’t thinking about memory leaks and code optimization in the exact same way in the past. With that said, Go is fast for development, build, and runtime. Very often there are trade-offs there. Like an interpreted language which may be quicker to some for development will lack in performance.
Go is not OOP
One thing I want you be clear about, is that Go is not quite object-oriented in the way that Java or Python users may be familiar with. Go does not support inheritance, rather composition.
There are no constructors. The struct is the main player and things are really based on the type of OOP you can accomplish within C. It’s not the end of the world, but your designs will look different from a language that supports inheritance.
Error handling
There are no exceptions and no error “handling” in Go. You have to deal with Tuple style return values. This is also very C influenced. You can wrap errors so that you can deal with typed error handling.
Modules & Packages
Go is very module centric. Go is very opinionated on how modules are handled and what has access to what. You can only have a single “main.go” which is your application entrypoint. You must be careful to design your system to handle cyclic imports correctly. This is where interfaces really come into the picture. The only way to control package visibility is determined by the case of the first letter of the variable or function. A lowercase entity is only available within a single package.
Handling many services
Some people like to take single use to an extreme and end up with a thousand tiny little functions. If that is called microservices…I do mini services.
I make small topic-centric handlers that are self-contained. A REST API will connect to that service. To handle the fact that Go only supports a single main.go per module I am using a dispatcher.
package commons
type ApplicationContext struct {
FunctionName string //Used to determine which dispatcher is used
Ctx *lambdacontext.LambdaContext //Ref to the context of the lambda
Event map[string]any //The event payload
Token *jwt.Token //Ref. JWT Token if applicable
Conf *conf.Conf //Ref. conf instance
Outputs map[string]string //All cloud formation outputs
Clients *Clients //Reference to all clients
}
type Dispatcher interface {
Eval(Context *ApplicationContext) bool //Should this dispatcher be used for this call
Invoke(Context *ApplicationContext) (any, error) //Invoke the dispatcher
IsHTTPPRoxyRequest(Context *ApplicationContext) bool //Is an HTTP request
RequiresAuthentication(Context *ApplicationContext) bool //Force auth check
UsesStripe(Context *ApplicationContext) bool //Instantiate stripe client
UsesDB(Context *ApplicationContext) bool //Instantiate DB
}
This is our Dispatcher interface and our ApplicationContext. Our Clients are instances of each client that are used.
Our entire stack is within cloud formation. To make it easy to access stack resources. Here is a nice little function:
package util
var _outputs map[string]string = map[string]string{}
var stackNames = []string{"ACTStack", "ACTApi"}
func GetStackOutputs() map[string]string {
if len(_outputs) > 0 {
return _outputs
} else {
cf := cloudformation.NewFromConfig(GetConf(nil))
for _, stack := range stackNames {
out, err := cf.DescribeStacks(context.TODO(), &cloudformation.DescribeStacksInput{
StackName: aws.String(stack),
})
if err != nil {
log.Error(err.Error())
}
arn := regexp.MustCompile("arn:aws:cloudformation:\\w{2}-\\w{4}-\\d:(\\d{12})")
_outputs["AccountId"] = arn.FindStringSubmatch(*out.Stacks[0].StackId)[1]
for _, o := range out.Stacks[0].Outputs {
key := *o.OutputKey
key = strings.Replace(key, "Export", "", -1)
_outputs[key] = *o.OutputValue
}
}
}
return _outputs
}
To support dynamic configuration I created simple support for YAML based configuration files. These are generic and environment specific. All you need to do create a struct that reflects your needs and write the YAML.
There is a popular YAML marshaller that I use then return it. that is the GetConf() function.
Dispatch
package main
func Dispatch(Context *commons.ApplicationContext) (any, error) {
for _, dispatcher := range dispatchers {
if dispatcher.Eval(Context) {
token, err := util.Authenticate(dispatcher, Context)
Context.Token = token
if err != nil {
return events.APIGatewayProxyResponse{StatusCode: 401}, nil
}
test.GetClients(Context, dispatcher)
output, err := dispatcher.Invoke(Context)
if err != nil {
log.Error(err)
statusCode := 500
if errors.Is(err, commons.ForbiddenError) {
statusCode = 403
}
return events.APIGatewayProxyResponse{
StatusCode: statusCode,
Headers: GetCorsHeaders(Context),
Body: err.Error(),
}, nil
}
return ProcessHTTPRequest(dispatcher, Context, output)
}
}
return map[string]any{}, nil
}
We have an array of dispatchers one per module. The Eval() function determines if this is the appropriate dispatcher for the current invocation. The Authenticate will populate a jwt.Token as applicable and will enforce if specified.
If you look at line 10. That handles a scenario where authentication is required and fails. Line 20-21 is made for scenarios where depending on the output of the call a 403 would be returned.
This is an example of unwrapping errors and evaluating the error type.
Privacy
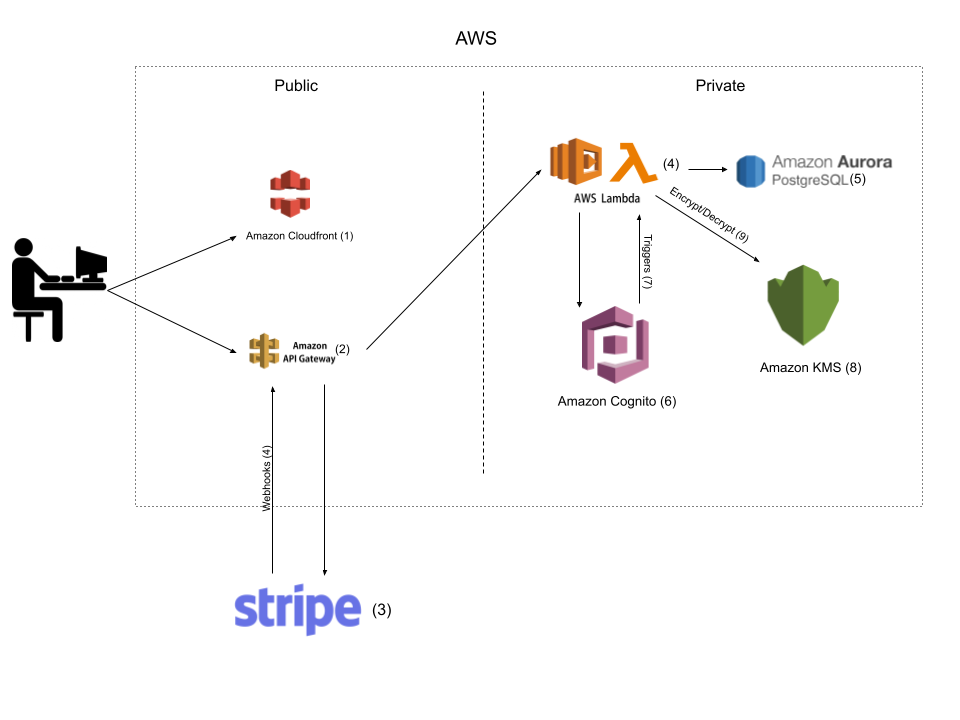
The second part of this article is how privacy first is approached. The basis of the system design is that the data is in three different systems that are actually naturally that way. I’m not really going out of my way to partition the data. The general goal is through data isolation and segmentation as well as encryption you can make it very difficult for even a highly privileged user to obtain this private information. Remember, we try to focus on preventing the plausible and likely, and we also try to deter the user and make it very difficult to access that data. So wherever data is isolated it should require at least access to two data stores for the data to have any meaning. The data by itself without the secondary data store is completely useless.
Cognito
The system begins with AWS Cognito. Using Cognito for user management is generally a pleasure and simple. We are utilizing the groups to track what group users are in. I am heavily enriching the JWT Token with data prior to the token being generated.
Now the user in Cognito is identified with a sub id which is a GUUID. Our other data storage is our relational database PostgreSQL which utilizes the user’s id
PostgreSQL
Without going into specifics for our application, the main takeway is all users utilize the id created in Cognito. So in my relational database I don’t actually have any user profile information (first name, last name, etc..). I do have much more complex data for the application. The private data is actually stored in PostgreSQL but it is encrypted using KMS. This encrypted data is only able to be decrypted by specific lambda functions that have access to the KMS key. Since the PostgreSQL data actually cannot be identified alone it creates another layer of security and isolation for that private information. Not that this is really needed, but it is how things best fit and was an added bonus.
Stripe
We are using stripe for payment processing. If we can easily look at stripe and figure out how much the payment are…that will remove the anonymity that we are striving for. It turns out that Stripe’s “Customer” does not require any information when created. Therefore, I can create a customer, attach a credit card, and make a payment without having any user information on Stripe. This means that we can have another layer of data isolation. The only way to connect that information for the user would be with the stripe customer id. We store the stripe customer id in PostgreSQL, but it is encrypted. We also store a one-way-hash for quick lookups for events.
OCR
Part of this system we have the user upload some tax forms. They are processed and data extracted. A small secret sauce is how I can do this without worrying about the social security numbers that are on these documents. Always remember that even if you don’t want to keep the sensitive data, if it runs through your system you are responsible for that data. Make sure you know what you are doing!
Conclusion
I want to summarize that the approaches I am using is how to handle sensitive data as well. But you better know what you are doing first. Here we are only talking about non-sensitive, but we are treating it like a hot potato. At no point are we letting privacy sacrifice the integrity of the application. I will say that with a very large database, some of these approaches will affect performance and should be dealt with on a case by case scenario.